6월 23일, 네이버 검색팀은 14억 건이 넘는 네이버 상품 정보에 대한 쇼핑 검색 품질 개편을 발표하였습니다.
이번 발표는 네이버 검색이 3년 간의 쇼핑 검색의 랭킹 모델 개선에 대한 발표 이후
네이버AI의 학습과 경험이 축적된 쇼핑 검색의 모델로의 개편 결과로 많은 관심을 모으고 있습니다.
약 3년 동안의 업데이트를 통해 네이버가 사용자의 검색 질의에 대한 품질을 개선하기 위해 네이버 AI와 머신러닝을 기반으로한 쇼핑 검색 모델을 개발하여
지속적으로 쇼핑 쿼리에 대한 만족도를 높이고 양질의 쇼핑 검색 결과 제공을 목표로 한다는 점에서 시사하는 바가 크다고 할 수 있습니다
검색의도와 상품의 특징이 잘 반영되는 트리 구조로의 전환
네이버 검색팀의 발표에 따르면 코로나 팬데믹 이후에도 쇼핑 검색 트래픽과 상품의 다양성은 지속적으로 증가됨에 따라
기존 선형 알고리즘의 취약점을 보완하는데 중점을 두고 있음을 확인할 수 있습니다.
그동안 네이버 쇼핑 검색은 상품의 대 카테고리에서 중 카테고리, 그리고, 검색어 단위로 랭킹을 학습하는 방식을 취해 왔다고 발표하였습니다.
구체적으로 랭킹에 사용하는 점수는 [가중치 * 랭킹요소(Feature)]의 값들을 더한 형태(Linear Weighted Sum)였습니다.
랭킹 수식은 단순하지만, 랭킹 수식에 사용하는 요소들은 사용자의 상품 선호도, 상품 정보 품질, 인기도를 반영할 수 있는 요소를
네이버 AI와 머신러닝에 기반한 고도화된 모델을 통해 추출하는 방식으로 상품 순위의 품질을 향상시켜 왔음을 네이버가 공개하였습니다.

네이버는 기존의 선형 모델이 적용하기 빠르며 해석이 직관적으로 가능하다는 장점이 있는 반면에
그러나 랭킹을 구성하기 위한 가중치 요소가 많아질수록 각 가중치의 의미는 흐려질 수 있고
조회 수, 리뷰 수, 상품 판매량같이 복합적으로 연관되어 있는 상품 요소들의 상관 관계를 정교하게 반영하지 못한다는 단점을 지적하고 있습니다.
또한 특정 요소의 가중치에 따라 다른 요소들의 점수가 매우 낮아도 검색 결과 상위에 노출될 가능성을 내재하고 있어
키워드와의 적합도가 낮은 상품이 상위에 도출되거나 검색 결과에 영향을 미치려는 어뷰징에 취약할 수 있다는 단점도 있음을 공개하였습니다.
쇼핑 검색 결과에서 까다로운 사용자의 의도를 이해하고 검색어에 적합한 환경을 제공하기 위한 네이버의 개선 과정이라고 볼 수 있습니다.
상품 단위의 다양한 랭킹 요소를 고려한 GradientBoosted Tree 기반 Learning to Rank 랭킹 모델 적용
네이버는 기존 선형 랭킹 모델의 단점을 보완하고 더욱 정교한 결과를 제공하기 위해
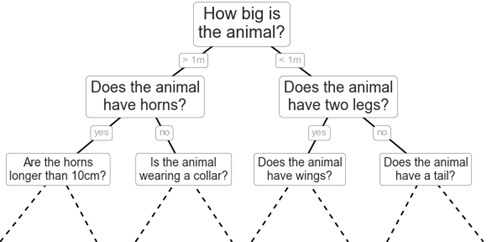
Gradient Boosted Decision Tree(GBDT) 기반 learning to rank 모델을 쇼핑 검색에 적용할 예정이라고 발표하였습니다.
GBDT(Gradient-boosted Decision Trees)는 학습 프로세스의 연속적인 단계를 통해 모델의 예측 값을 최적화하기 위한 머신러닝 기반의 기술입니다.
출처: jakevdp.github.io
GBDT 모델은 과거 상품 노출 성과와 사용자 반응을 이용해 최상의 검색 결과 만족도를 제공하는 방향으로 학습합니다.
이 모델은 최대 깊이 M인 N개의 Sub-tree를 바탕으로 검색어와 랭킹 요소들 간의 특징을 세밀하게 반영할 수 있다는 장점이 있습니다.
예를 들면, Tree 구조를 이용하여 검색어와 상품 간의 매칭 정확도가 낮은 경우 상품의 인기도가 아무리 높더라도 상위에 랭크되지 않을 수 있습니다.
또한, 사용자 클릭 대비 리뷰나 판매지수가 높은 경우 더 상위에 랭크될 수도 있습니다.
GBDT 참조:
https://towardsdatascience.com/gradient-boosted-decision-trees-explained-9259bd8205af
Wikipedia :
https://en.wikipedia.org/wiki/Gradient_boosting
네이버 쇼핑 검색 랭킹 모델 개선의 적용 사례
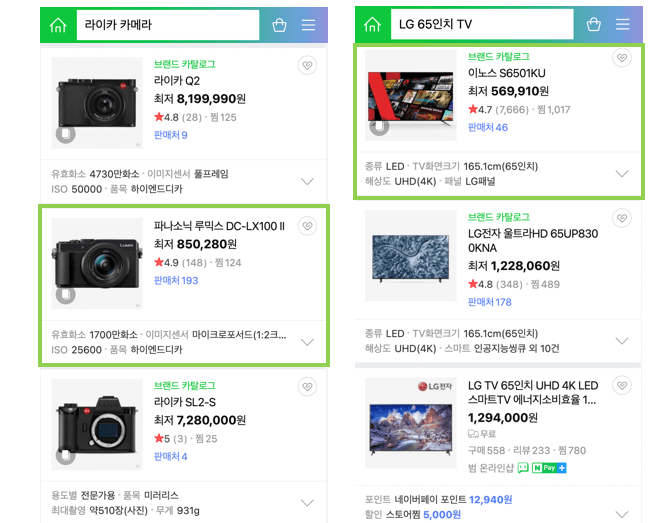
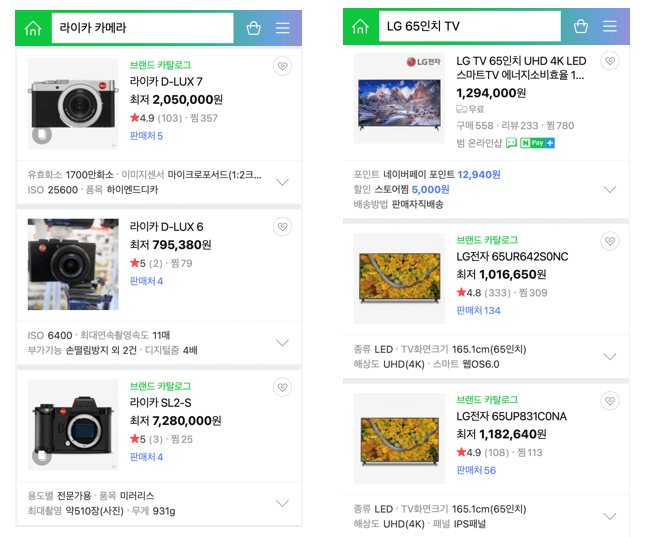
쇼핑 검색어: 라이카 카메라, LG 65인치 TV
화면 출처: 네이버 검색 블로그
적용 이전 검색 결과
검색어와 관련이 낮은 상품들이 결과로 노출됨
적용 이후검색 결과
검색어와 관련이 높고 사용자의 의도와 일치하는 검색 결과로 개선
출처: 네이버 검색 블로그
선형 모델에서 일부 검색어는 상품 카테고리는 유사하나, 연관도가 낮은 상품도 일부 노출되었습니다.
개편 시점에는 관련도가 높은 상품을 중심으로 노출될 예정입니다.
상품의 노출 지표와 품질이 낮은 검색결과도 상당수 개선되었음을 알 수 있었습니다.
적합도, 인기도, 신뢰도에 기반하는 네이버 쇼핑 검색 알고리즘의 이해
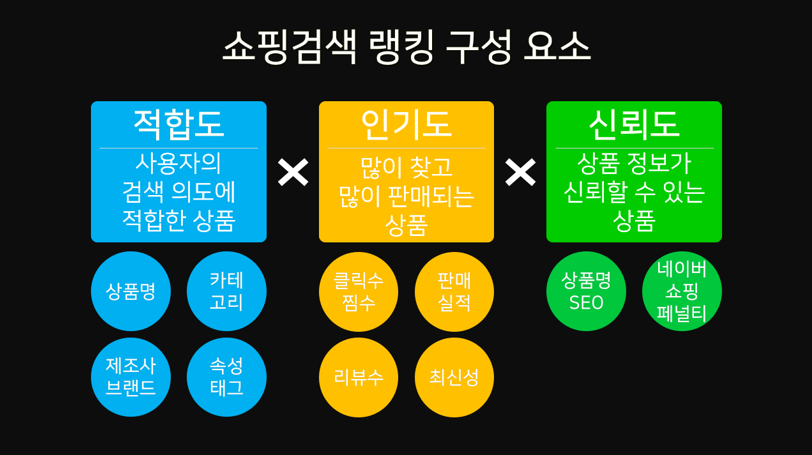
1. 적합도(Relevant)
사용자가 입력한 검색어가 상품명, 카테고리, 제조사/ 브랜드, 속성/ 태그 등 상품 정보의 어떤 항목과 연관도가 높은지,
검색어와 관련하여 어떤 카테고리의 선호도가 높은지를 산출하여 적합도로 반영됩니다.
A. 필드 연관도
예를 들어 검색어가 “나이키”인 경우 “나이키”는 브랜드 유형으로 인식되며,
상품명에 “나이키”가 기입되어 있는 것보다 브랜드에 “나이키”로 매칭되어 있는 것이 우선적으로 노출됩니다.
B. 카테고리 선호도
“블라우스” 검색어의 경우는 여러 카테고리 상품이 검색되지만, [패션의류>여성의류>블라우스] 카테고리의 선호도가 매우 높습니다.
검색 알고리즘은 해당 카테고리의 상품을 먼저 보여줄 수 있게 추가 점수를 주게 됩니다.
2. 인기도(Popularity)
해당 상품이 가지는 클릭수, 판매실적, 구매평수, 찜수, 최신성 등의 고유한 요소를 카테고리 특성을 고려하여, 인기도로 반영됩니다.
인기도는 카테고리별로 다르게 구성되어 사용됩니다.
A. 클릭수(Clicks)
최근 7일 동안 쇼핑 검색에서 발생된 상품 클릭수를 지수화
B. 판매실적(Sales)
최근 2일/7일/30일 동안 쇼핑검색에서 발생한 판매수량/판매금액을 지수화
스마트스토어의 판매실적, 리뷰수는 네이버페이를 통해 자동 연동, 부정 거래가 있을 경우 페널티 부여
C. 구매평수(User Reviews)
개별 상품의 리뷰수를 카테고리별 상대적으로 환산하여 지수화
D. 찜수(Bookmark)
개별 상품의 찜수를 카테고리별 상대적으로 환산하여 지수화
E. 최신성(Freshness)
상품의 쇼핑DB 등록일을 기준으로 상대적 지수화, 신상품 한시적 노출 유도
3. 신뢰도(Trust)
네이버쇼핑 페널티, 상품명 SEO 등의 요소를 통해 해당 상품이 이용자에게 신뢰를 줄 수 있는지는 산출하여, 신뢰도로 반영합니다.
A. 네이버쇼핑 페널티
구매평/판매실적 어뷰징, 상품정보 어뷰징 등에 대한 상품/몰단위 페널티 부여
B. 상품명 SEO 스코어
상품명 가이드라인을 벗어난 상품에 대한 페널티 부여
네이버의 검색팀은 이번 업데이트에 대해
단순히 클릭이나 매출이 높다고 검색어와 적합도가 떨어지는 상품이 상위에 노출되는 리스팅 빈도가 감소했으며,
검색어의 노출 성과 지표도 개선되었음을 강조하고 있습니다.
쇼핑 검색에서 더 적합한 상품을 상위에 노출하고,
사용자가 원하는 상품이 반영되도록 쇼핑 검색의 개편을 기대하게 됩니다.
출처: 네이버 검색 블로그